Getting data out of the blockchain and into the wider world
With the first public release of MultiChain, way back in 2015, we saw interest in blockchain applications from a surprising direction. While we had originally designed MultiChain to enable the issuance, transfer and custody of digital assets, an increasing number of users were interested in using it for data-oriented applications.
In these use cases, the blockchain’s purpose is to enable the storage and retrieval of general purpose information, which need not be financial in nature. The motivation for using a blockchain rather than a regular database is to avoid relying on a trusted intermediary to host and maintain that database. For commercial, regulatory or political reasons, the database’s users want this to be a distributed rather than a centralized responsibility.
The Evolution of Streams
In response to this feedback, in 2016 we introduced MultiChain streams, which provide a simple abstraction for the storage, indexing and retrieval of general data on a blockchain. A chain can contain any number of streams, each of which can be restricted for writing by certain addresses. Each stream item is tagged by the address of its publisher as well as an optional key for future retrieval. Each node can independently decide whether to subscribe to each stream, indexing its items in real-time for rapid retrieval by key, publisher, time, block, or position. Streams were an instant hit with MultiChain’s users and strongly differentiated it from other enterprise blockchain platforms.
In 2017, streams were extended to support native JSON and Unicode text, multiple keys per item and multiple items per transaction. This last change allows over 10,000 individual data items to be published per second on high-end hardware. Then in 2018, we added seamless support for off-chain data, in which only a hash of some data is published on-chain, and the data itself is delivered off-chain to nodes who want it. And later that year we released MultiChain 2.0 Community with Smart Filters, allowing custom JavaScript code to perform arbitrary validation of stream items.
During 2019 our focus turned to MultiChain 2.0 Enterprise, the commercial version of MultiChain for larger customers. The first Enterprise Demo leveraged off-chain data in streams to allow read permissioning, encrypted data delivery, and the selective retrieval and purging of individual items. As always, the underlying complexity is hidden behind a simple set of APIs relating to permissions and stream items. With streams, our goal has consistently been to help developers focus on their application’s data, and not worry about the blockchain running behind the scenes.
The Database Dilemma
As MultiChain streams have continued to evolve, we’ve been faced with a constant dilemma. For reading and analyzing the data in a stream, should MultiChain go down the path of becoming a fully-fledged database? Should it be offering JSON field indexing, optimized querying and advanced reporting? If so, which database paradigm should it use – relational (like MySQL or SQL Server), NoSQL (MongoDB or Cassandra), search (Elastic or Solr), time-series (InfluxDB) or in-memory (SAP HANA)? After all, there are blockchain use cases suited to each of those approaches.
One option we considered is using an external database as MultiChain’s primary data store, instead of the current combination of embedded LevelDB and binary files. This strategy was adopted by Chain Core (discontinued), Postchain (not yet public) and is available as an option in Hyperledger Fabric. But ultimately we decided against this approach, because of the risks of depending on an external process. You don’t really want your blockchain node to freeze because it lost its database connection, or because someone is running a complex query on its data store.
Another factor to consider is technology and integration agnosticism. In a blockchain network spanning multiple organizations, each participant will have their own preferences regarding database technology. They will already have applications, tools and workflows built on the platforms that suit their needs. So in choosing any particular database, or even in offering a few options, we’d end up making some users unhappy. Just as each blockchain participant can run their node on a wide variety of Linux flavors, they should be able to integrate with their database of choice.
Introducing MultiChain Feeds
Today we’re delighted to release our approach to database integration – MultiChain Feeds. A feed is a real-time on-disk binary log of the events relating to one or more blockchain streams, for reading by external processes. We are also offering the open source MultiChain Feed Adapter which can read a feed and automatically replicate its content to a Postgres, MySQL or MongoDB database (or several at once). The adapter is written in Python and has a liberal license, so it can be easily modified to support additional databases or to add data filtering and transformation. (We’ve also documented the feed file format for those who want to write a parser in another language.)
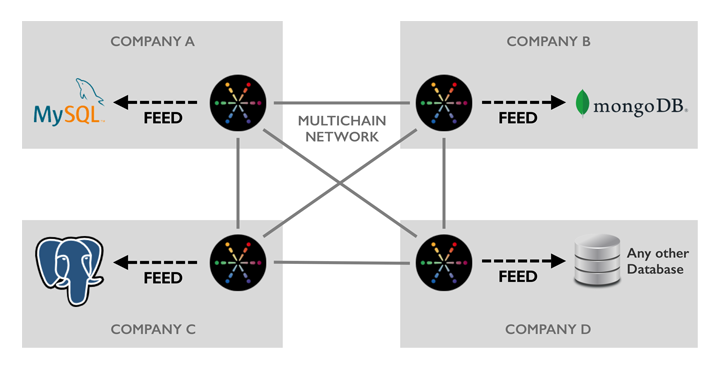
A node need not subscribe to a stream in order to replicate its events to a feed. This allows MultiChain’s built-in stream indexing to be completely bypassed, to save time and disk space. Feeds also reflect the retrieval and purging of off-chain data, and can report on the arrival of new blocks on the chain. In order to save on disk space, you can control exactly which events are written to a feed, and which fields are recorded for each of those events. In addition, feed files are rotated daily and there’s a simple purge command to remove files after processing.
Why are MultiChain feeds written to disk, rather than streamed between processes or over the network? Because we want them to serve as an ultra-reliable replication log that is resilient to database downtime, system crashes, power loss and the like. By using disk files, we can guarantee durability, and allow the target database to be updated asynchronously. If for some reason this database becomes overloaded or disconnected, MultiChain can continue operating without interruption, and the database will catch up once things return to normal.
Getting Started with Feeds
Feeds are integrated into the latest demo/beta of MultiChain Enterprise, which is available for download now. Get started by reading the documentation for the MultiChain Feed Adapter, or reviewing the feed-related APIs. We’d love to hear your feedback on this feature and how we can expand it in future.
With the release of feeds, version 2.0 of MultiChain Enterprise is now feature complete – see the Download and Install page for a full comparison between the Community and Enterprise editions. Over the next couple of months we’ll be completing its testing and optimization, and expect it to be ready for production around the end of Q1. In the meantime, for information about MultiChain Enterprise licensing or pricing, please don’t hesitate to get in touch.
Please post any comments on LinkedIn.